
Let’s be clear. This blog is not about AWS IoT. At Yatis most of our devices are GPS devices which do not use MQTT – they use TCP. We cannot use AWS IoT for such devices. However, you can use the serverless offerings in both compute and database to add massive scale to your TCP based IoT platform. In this blog we will discuss, how we added serverless components to our otherwise pure EC2 based offering, the benefits and downsides to doing so.
Connectivity Management for Devices
As I mentioned earlier, most devices on our platform are GPS tracking devices that communicate using TCP. The communication is two-way, the devices send information like GPS, engine health, 3-axis acceleration, etc and the server sends acknowledgement, configuration and OTA (over the air) updates to the devices.
The devices are assigned IP addresses dynamically. The device initiates a connection to the server and establishes a TCP socket. The server approve the device and may send an acknowledgement based on the device type. Note that the server cannot initiate a connection with the device. The device initiates communication and IP address of the device keeps changing with every new connection.
The communication over the TCP socket is in binary and optimized. The data consumed by the devices is low. An average device on our platform generates less 5MB of data. The overheads of initiating and maintaining sockets add another 5MB. So each devices produces very little data, but there are a lot of devices that are in constant communication with servers.
Boost Scale with AWS Serverless Lambda and Dynamo

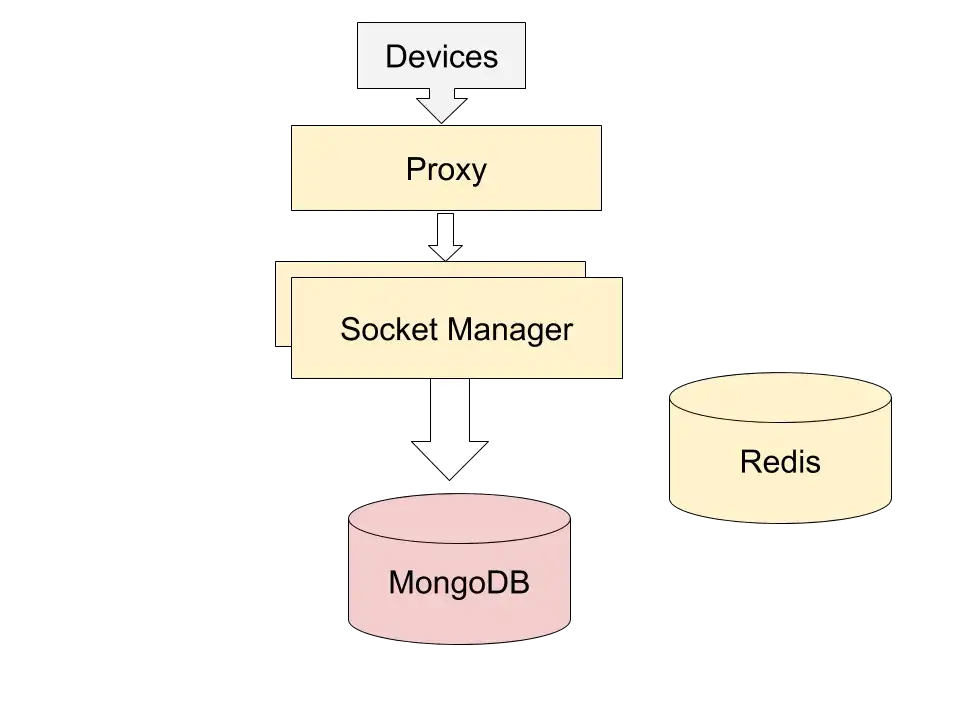
Figure A: IoT Framework with EC2 only
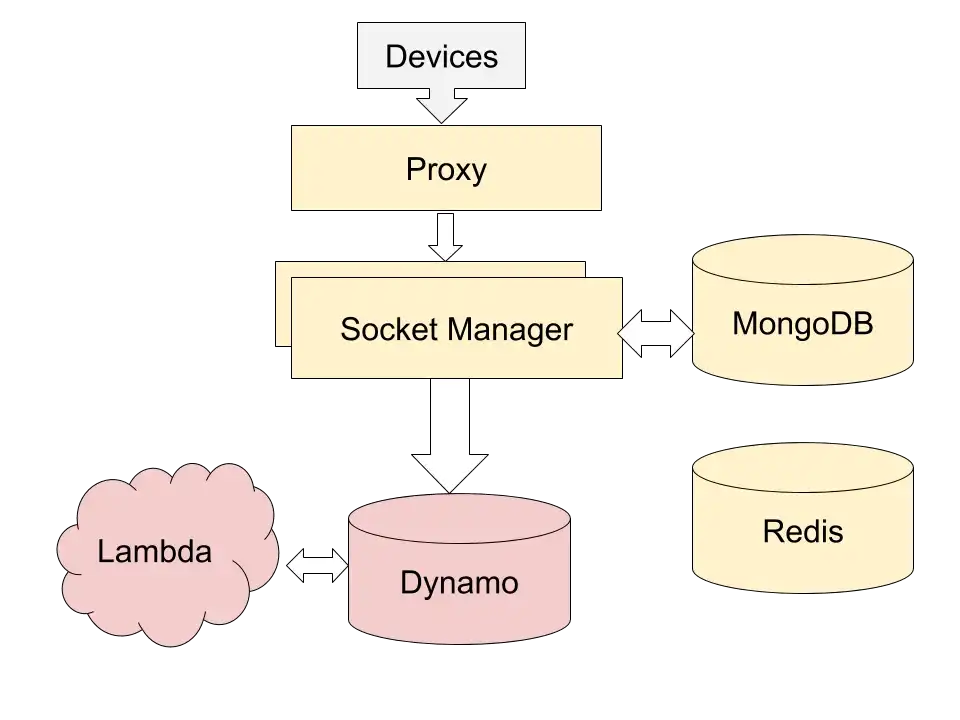
Figure B: IoT Framework with Lambda and Dynamo
The first illustration A shows an implementation with only EC2 machines, whereas Figure B shows the implementation with serverless AWS compute and AWS Dynamo.
In the old implementation, the devices talk to the proxy which distributes the work to a farm of device connectors. The device connectors review the data packet, translate the data, save it to the DB. They also do the socket management and communicate with the devices. The business logic of identifying the device and translation is done in this layer.
In the new implementation, the proxy distributes the work to socket managers. The socket managers here manage communication and the sockets. They do some error checking, get metadata for the device from MongoDB or Redis, identify the device type and write the data into Dynamo DB table. Each entry into this dynamo DB table triggers a lambda function, which contains the business logic to translate the binary data that can be saved or transmitted as locations, alarms, or parametric data. The lambda function saves all translated data in Dynamo DB.
Delineation of Socket Management and Business Logic
In the old framework, the device connectors on EC2 did both socket management and the business logic. Leveraging lambda, the new framework separates these core functions keeps the socket management layer in EC2 and moves the heavy lifting to lambda. We noticed about 5 times reduction in load on the EC2 machines in the new framework as compared to older EC2 exclusive framework. Since AWS Lambda scales seamlessly, the framework would support many more devices.
Dynamo and MongoDB
In the new framework we save all data generated by devices like GPS, temperature, fuel level, journeys, alarms in AWS Dynamo. We kept the metadata related to the devices like vehicle name, user name in Mongo. The data from the devices is a constant stream and scales quickly. Currently our Dynamo DB has about 1000 times more data than MongoDB. We now use much smaller and fewer shards for our MongoDB installation than previously.
The comparison between Mongo and Dynamo was a little more complicated. For us the main advantages of Mongo over Dynamo are
- Mongo is much easier to code in. Dynamo is a lot more complicated. With Dynamo you need many more lines of code to do the same.
- Both Mongo and Dynamo are NoSQL DBs. However, Mongo enables some relational capabilities with populate. Dynamo does not have anything similar.
Why Dynamo is Cheaper
The main reasons for us to add Dynamo and make it our main database is cost. Dynamo helps you reduce cost in multiple way
- Easier management -Dynamo is a genuine DB as a service, where I do not have to worry about provisioning, number of shards, size of hard disks or RAMs. It frees up scarce engineering resources from DB management.
- Autoscaling – The number of devices and frequency with which they communicate is not constant. There are peaks and lulls. Also fewer customers check the application at night. With Autoscaling, we only allocate what we need.
- Pay for what you use – As most services, we cannot afford downtime. So our Mongo implementation was over-allocated. Usually we were using only a small fraction of its capability. With Dynamo, we allocate and pay for what we need, which keeps the overall cost low.
- Granular Measurement – ‘You can’t improve what you don’t measure’ is a very relevant axiom. With Dynamos tools, we could measure the usage on every index and optimize our queries and indexing strategies so that we used less resources.
Summary
Serverless compute and database technologies are a revolution. EC2’s are easy to use and a direct extension of using standalone computers, where you still worry about size of the machine and provisioning. Dynamo and Lambda are genuine cloud services, with which you can focus on only what your application and not on the management of hardware or DBs. We could use these services in adding scale and reducing cost for our IoT framework.
Featured Image Credit: https://hackernoon.com/how-can-serverless-computing-benefit-your-startup-67503e08f76e